Table of Contents
Why CDC is eating the traditional “nightly batch” architecture – and why most organizations realize it a year too late
Most enterprise data pipelines still move data the way we did in 2010.
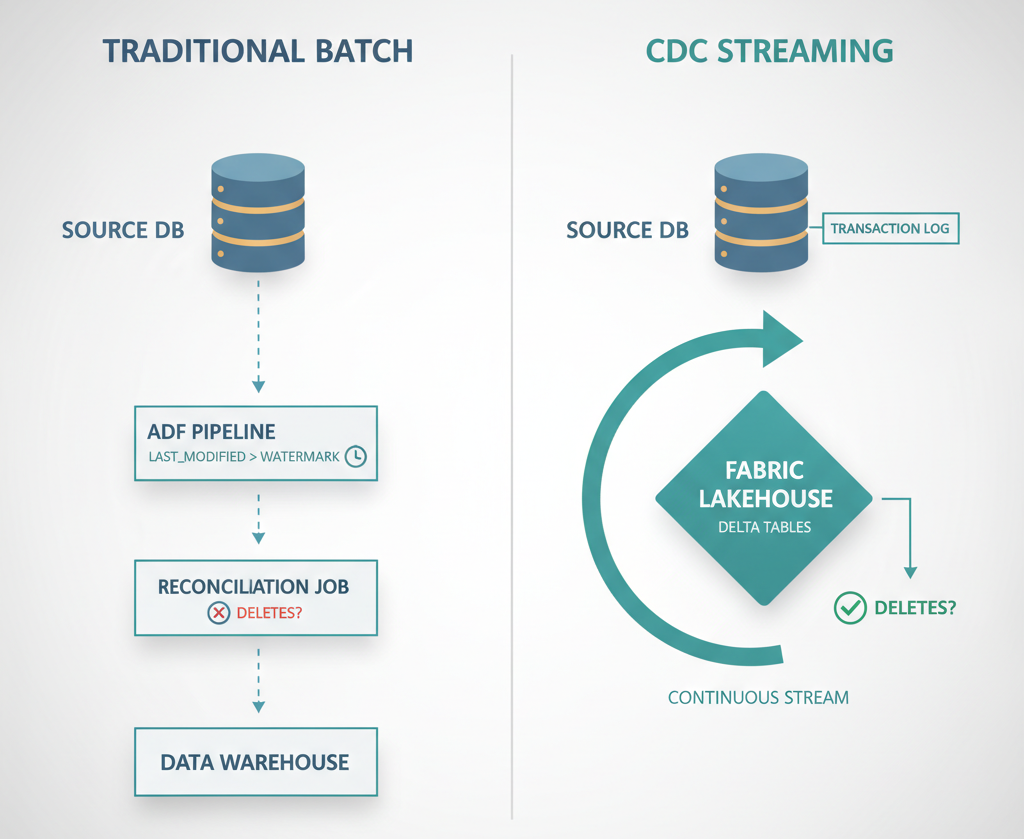
A schedule fires at 2 AM. A job pulls “changed” rows from a source system using a last_modified timestamp as watermark approach. Maybe it’s lucky and the clocks are in sync. Maybe it’s unlucky and a deleted row quietly vanishes without a trace. By 8 AM, dashboards are green and everyone assumes the data is right. It usually isn’t.
The Lie We Tell Ourselves About “Incremental Loads”
Ask any data engineer how their nightly sync works, and you’ll hear some version of this:
“We pull rows where
modified_at > last_run_timeand upsert them into the warehouse.”
That sentence hides three problems that only surface in production.
First, timestamp-based incremental loads don’t see deletes. A row removed from the source never appears in your query, so your destination keeps a ghost. AR aging reports show a customer who doesn’t exist. Inventory shows stock that was scrapped last month. Finance reconciles against a phantom.
Second, they rely on the source keeping accurate modification timestamps. Many ERP systems don’t. Worse, application bugs or bulk imports sometimes update rows without updating the timestamp at all.
Third, they scale badly. A 200-million-row ledger table with daily incremental pulls takes an hour on a good day. When the business wants hourly refreshes, the answer is a bigger VM. When they want near-real-time, the answer is usually a rewrite.
This is the quiet tax of the traditional approach: it looks simple, but the reliability and the freshness both degrade as the business grows.
What Change Data Capture Actually Does Differently
CDC (Change Data Capture) doesn’t ask the source “what changed since yesterday?” It reads the source’s own transaction log and streams every insert, update, and delete in the order they happened.
That one design change fixes all three problems:
- Deletes are captured because the log recorded them.
- Timestamps don’t matter because the log is the source of truth for change order.
- Volume scales because you’re shipping deltas, not scanning tables.
Here’s where most teams get this wrong: they assume CDC is a feature they can toggle on a nightly job. It isn’t. CDC is a different architecture. It replaces a pull model with a push-from-the-log model. That’s why the cost savings, freshness, and correctness all come together where you’re not optimizing an old pipeline, but eliminating it.
Why Microsoft Quietly Rewrote Its Own Playbook
Two things happened in 2025 that tell you where Microsoft expects enterprise analytics to go.
In November 2025, Mirroring for SQL Server became GA in Microsoft Fabric. Any SQL Server database on-prem, in a VM, or managed can now continuously replicate into OneLake as Delta tables. No pipeline to build. No incremental watermark logic. The storage is free inside your Fabric capacity allowance.
In parallel, Copy Job in Data Factory added CDC support. For sources that aren’t directly mirrorable, Copy Job handles the incremental copy pattern as a first-class feature instead of something you stitch together.
Both of these quietly make the old approach Azure Data Factory pipelines with watermarks, custom delete-reconciliation jobs, and webhook handlers, look like yesterday’s architecture.
The signal is clear: Microsoft is betting that enterprises want less pipeline code, not more.
The Trade-Off Nobody Mentions
CDC isn’t free.
The source DBA has to enable it, either SQL Server CDC or Change Tracking which adds a small write-path overhead on the transactional database. On a healthy SQL Server instance, this is low single-digit percent. On a system that’s already memory-constrained or running tight on log I/O, it can be enough to notice.
There’s also a one-time organizational cost. The DBA team, the BC partner (if the source is an ERP), and the analytics team all have to agree on what gets CDC-enabled, who holds the service credentials, and what happens when the schema changes. Traditional ETL often ran entirely inside the analytics team’s silo. CDC pulls the DBA into the conversation permanently.
The payoff is real, fewer bugs, lower latency, no ghost rows. But the first 60 days of a CDC migration include more cross-team meetings than most teams expect.
Where the Traditional Approach Still Wins
Let’s be honest. CDC isn’t always the right call.
- Small data volumes, infrequent refreshes. If the business genuinely wants a weekly snapshot of a 10,000-row table, a scheduled pipeline is fine.
- Sources that don’t support CDC. Flat files, legacy systems without transaction logs, or APIs without a change feed can’t play. Stick with pull-based patterns.
- One-time migrations. A BACPAC export or full-table copy is still the fastest way to do a historical load.
- Highly regulated environments where every hop is audited. Some clients prefer the auditability of discrete batch jobs over a continuous stream they have to monitor differently.
The rule of thumb: if your business asks for anything faster than daily refreshes, or if deletes matter, CDC is already the cheaper architecture.
The Hidden Cost Story
CDC changes the cost curve, not just the latency curve.
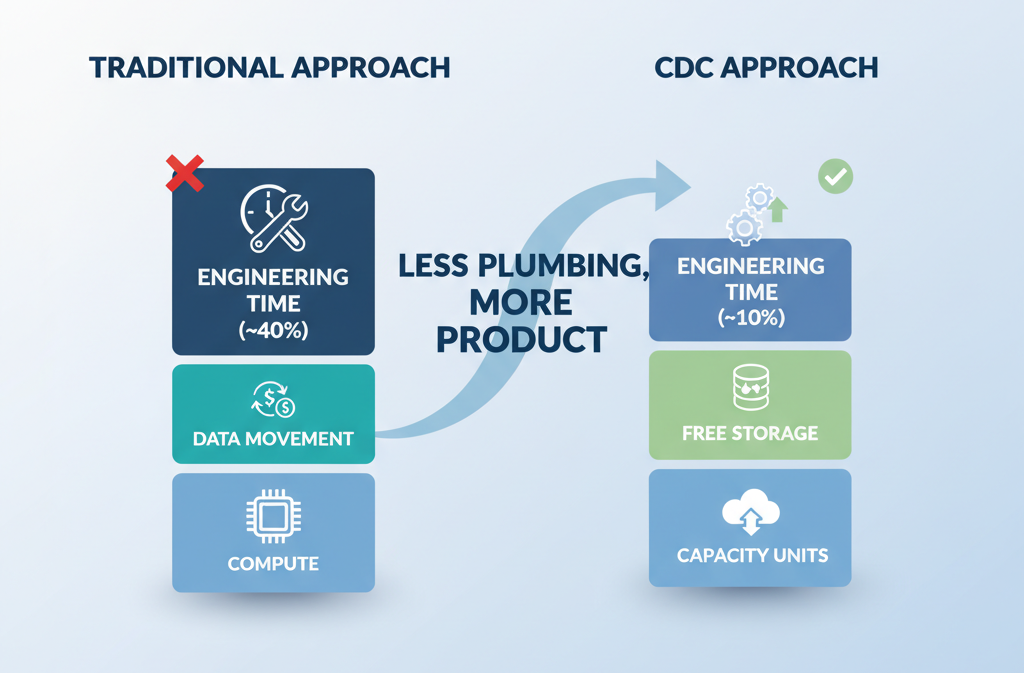
A traditional pipeline charges you three times: compute to run it, data movement per GB, and developer hours to maintain watermark logic and delete-reconciliation. The third is the expensive one. A well-built ADF pipeline with delete handling, failure retries, and schema-drift alerts is measured in weeks of engineering.
CDC through Fabric Mirroring charges you mostly for the capacity you’re already paying for. The mirrored storage is free inside your F-SKU. The apply is continuous and managed. There’s no watermark code to maintain, no reconciliation job to babysit, no webhook subscription renewing every three days.
The cost conversation that used to be “how much are we spending on Azure services?” becomes “how much engineering time are we not spending?”
A Scenario That Makes It Concrete
Imagine a mid-market manufacturer running Business Central on-premises. Fifteen tables feed two Power BI reports that finance and operations use every morning. The current setup is a handful of ADF pipelines built two years ago.
Every few weeks, a customer or an item that was deleted in BC lingers in the reports. The data team writes a ticket, patches the reconciliation logic, and moves on. The fix never sticks for long because the next schema change or bulk import exposes a new gap.
Swap in Fabric Mirroring for SQL Server via the On-premises Data Gateway, point it at the same BC database, and the entire problem class disappears. Deletes are captured. Inserts are captured. Updates are captured. The reconciliation backlog goes to zero. The data team redirects the hours they used to spend on pipeline firefighting to building the gold-layer business logic the CFO actually asked for nine months ago.
That’s the shift in one paragraph. Less plumbing. More product.
What Decision-Makers Should Actually Do
If you’re a CIO, CDO, or enterprise architect looking at this landscape today, here’s the honest take.
Don’t rewrite every pipeline tomorrow. That’s a waste of money and change-management capital. Most of your existing batch jobs are fine.
Do rewrite the painful ones. If you have a pipeline that has cost you more than two production incidents in the last year, or one where “the data is slightly off” is a recurring Slack thread, that pipeline is a candidate. CDC will usually pay for itself inside a quarter.
Do check whether your source systems can even support CDC. SQL Server, Azure SQL, PostgreSQL, and an expanding list of others are supported. Some ERP systems are not, and you’ll need a different pattern.
Do start with the GA path, not the preview path. For on-prem SQL Server sources, Mirroring is GA. For others, Copy Job CDC is preview. In production, stay on GA unless you have a specific reason not to.
Do involve your DBA team from day one. The architecture only works if they’re bought in. Surprising them with a CDC request after you’ve signed the Fabric contract is a recipe for a stalled project.
The One-Line Version
If your analytics platform still treats data movement as a scheduled job problem, you’re solving 2015’s problem with 2015’s tools. The sources have logs. The destinations want streams. The engineering bill for maintaining the gap in the middle is the largest line item you’re not measuring.
CDC is not a feature. It’s the new default. The organizations that recognize that early spend the next three years building insight. The ones that don’t spend those three years fixing pipelines. Choose accordingly.