Table of Contents
The most dangerous moment in any Copilot Studio deployment is the demo that goes well. A clean happy-path conversation, a smart tool call, a fluent summary. Leadership is sold. Budget is approved. The team moves on to the next use case.
Nobody notices for ninety days that the agent’s answer quality has quietly drifted, that tool-selection accuracy has dropped, that escalation rates are climbing, or that a certain phrasing is now bypassing a content moderation rule that used to catch it.
This is the unglamorous part of enterprise AI that leadership keeps underfunding. Evaluation is not a dashboard you buy. Evaluation is an operating discipline you build.
The Orchestration Switch Almost No One Thinks Through
Here is where the story starts. The moment you turn on generative orchestration, Copilot Studio stops being a deterministic chatbot. The agent now picks topics, tools, knowledge sources, and even child agents at runtime, based on inference.
That single toggle changes everything about how you have to test.
You can no longer script the happy path and call it good. The path itself is chosen on the fly. Two identical user inputs can take different paths, based on prior context, session state, or tiny phrasing variation. The traditional QA playbook (record conversation, replay conversation, assert on outputs) does not hold up.
Teams that do not rebuild their evaluation layer for this reality end up shipping agents they do not understand. That works until it does not.
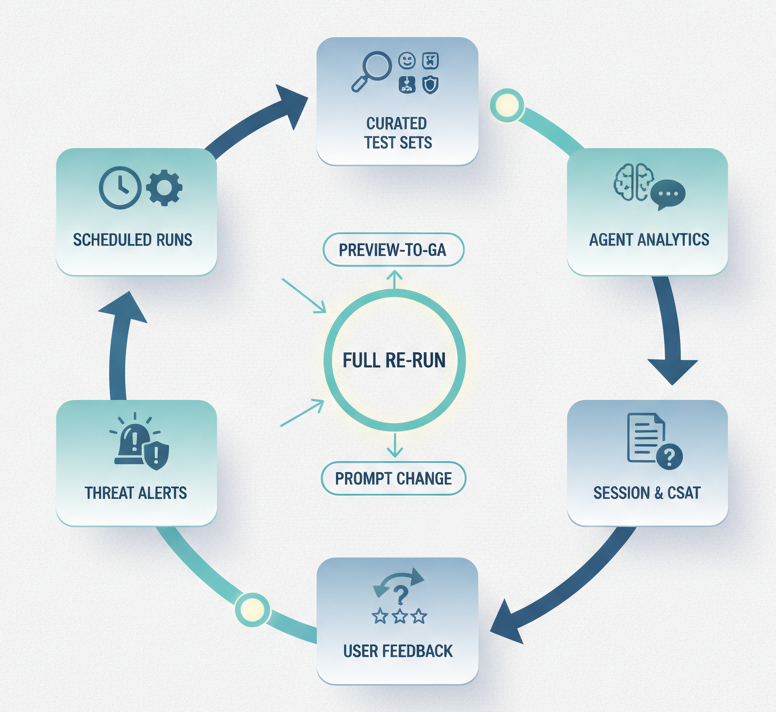
The Evaluation Stack Copilot Studio Actually Gives You
Copilot Studio ships a surprisingly complete evaluation toolkit. Most teams use only a fraction of it.
Test sets let you define representative inputs, expected behaviours, and pass/fail conditions. Now with validated CSV templates, so format errors stop eating your sprint.
Evaluation methods let you grade outputs, not just on exact match, but on correctness, grounding, style, and other dimensions. This is where non-deterministic outputs stop being untestable.
Autonomous agent health analytics track whether your autonomous agents do what they should, how often, and with what outcomes. They include a threat detection surface that tells you when published agents are probed or attacked.
Conversational analytics track answer rate and quality, grouping unresolved questions by theme. You can see where the knowledge gaps accumulate. This data feeds directly into the next version of your test set.
Transcripts with CSAT give you the ground-truth user reaction. Not just internal metrics.
That is five distinct layers of observability. Most teams use one of them.
The Reason Non-Deterministic Testing Is Hard
Here is where this stops being a tooling problem and becomes an operating discipline problem.
The first thing teams discover on trying to write test sets for a generatively orchestrated agent: they do not know what “correct” looks like. The response varied slightly. Is that a bug or acceptable variation? The tool got called with different parameters than last time. Is that smarter behaviour or drift? The agent refused a request that it used to answer. Is that improved moderation or a regression?
These questions have no universal answer. Every enterprise has to define, in writing, what constitutes acceptable behaviour for each task. The documentation calls this “choose evaluation methods.” The reality: choose what you mean by quality, then test for that.
That is a product decision, not a technical one. Most organisations do not have anyone whose job it is to make it.
The Drift Nobody Budgets For
Models drift. Prompts drift. Knowledge sources drift. User behaviour drifts.
Your agent was evaluated against a 2025 model. Microsoft upgrades the foundation model quietly in the background. Prompt behaviour shifts subtly. Your test set, which was passing, is now passing with slightly different outputs. Nobody notices. Nobody reruns the tests weekly.
Three months later, a user complaint surfaces. Logs are pulled. The agent stopped pulling from one of three knowledge sources three weeks ago, following a reindexing failure nobody was paged on.
Nothing broke. Nothing threw an exception. The agent just got worse.
Evaluation is the only thing that catches silent regression. That is the reason it has to be continuous, not one-off.
The Moderation Problem Most Teams Underestimate
Copilot Studio now lets you configure content moderation sensitivity per prompt. Hate/fairness, sexual, violence, self-harm. Low or high sensitivity settings for managed models.
This is a feature and a liability. A feature: regulated workloads need fine-grained control. A liability: “we set it to low so it stops blocking legitimate document processing” has a way of turning into “we disabled moderation. It kept getting in the way.”
Your evaluation layer has to include adversarial prompts. The kind a bored employee or a curious external user will try. Validate that moderation behaves the way your policy says it should. Every time. Not once at launch.
Threat detection on published agents helps, but only with someone watching it. Build the review cadence before you need it.
The Cost of Not Doing This
A clean evaluation layer costs money. A missing one costs more, in a less predictable way.
Incidents find you. A wrong answer in a customer-facing agent generates a support ticket, a social media screenshot, or, worst case, a regulatory complaint. Time to fix is compounded. You cannot reproduce the failure. You do not have the test set. You do not have the transcripts in one searchable place. You do not know whether this was a one-off or a pattern.
Meanwhile, teams without evaluation discipline are the ones who say “we should really retrain” or “we should really switch models.” They spend heavily on changes that are not actually solving their quality problem. They cannot measure whether any change helps.
Evaluation is the foundation that makes every other AI investment auditable.
Where the Quality Problem Actually Sits
Let’s be blunt about an uncomfortable truth.
Most Copilot Studio agents that are underperforming are not underperforming from the model. They are underperforming from bad prompts, dirty knowledge sources, ambiguous topics, or tool descriptions that confuse the orchestrator.
You cannot see any of that without evaluation. Without evaluation, teams tend to blame the foundation model. Blaming the model is the easiest story to tell leadership. That story slows down the actual fix.
The organisations getting real value from Copilot Studio are the ones who can confidently point at their quality metrics and say “the model is fine, our knowledge curation needs work,” or the reverse. That confidence is not a feature. It is built.
A Scenario That Will Feel Familiar
A services firm launched an internal HR agent. Pilot went well. CSAT scores were solid at 4.2 out of 5. Leadership greenlit rollout to 20,000 employees.
Six weeks in, CSAT drifted to 3.6. The agent was refusing to answer benefits questions it used to handle. The team assumed the model had changed. They opened a support ticket with Microsoft.
The actual root cause: a well-meaning HR admin had updated the benefits SharePoint library with a new set of documents. One of those had stricter confidentiality metadata. The agent was now refusing to surface content from that library for users without the new permission. Moderation was fine. The model was fine. The permissions boundary had changed. Nobody had caught it.
Evaluation would have flagged the regression on the next scheduled run. Without it, it took three weeks and a pile of angry tickets.
What Decision-Makers Should Fund, Right Now
Budget evaluation as a permanent operating cost. Not a launch task. Somewhere between five and fifteen percent of the total AI programme should go into evaluation infrastructure, test set curation, and analytics review.
Put a named owner on quality for every production agent. Not a shared mailbox. A person whose job it is to watch the autonomous agent health dashboard and the threat detection feed.
Build the test set as a living artifact. Every unresolved question, every CSAT drop, every moderation bypass becomes a new test case. That is how your evaluation layer gets sharper over time, instead of staler.
Make re-evaluation a gate, not a courtesy. Every preview-to-GA migration, every connector upgrade, every prompt change, every knowledge-source refresh triggers a full test-set rerun. If that is too expensive to do often, your test set is too expensive. Fix it at the start of the project, not at the end.
Frame all of this for your executive team as what it is. The only mechanism by which you can defend your agent’s behaviour to a regulator, a customer, or a board. The teams with that defence are calm. The teams without are one screenshot away from a bad week.
Generative orchestration gives you astonishing capability. Evaluation is what turns that capability into something you can keep in production for years instead of months. Do not skip it. Do not underfund it. Do not assume the dashboard is enough.
It is the least glamorous part of the programme. It is the part that decides whether the programme survives its first real incident.