Table of Contents
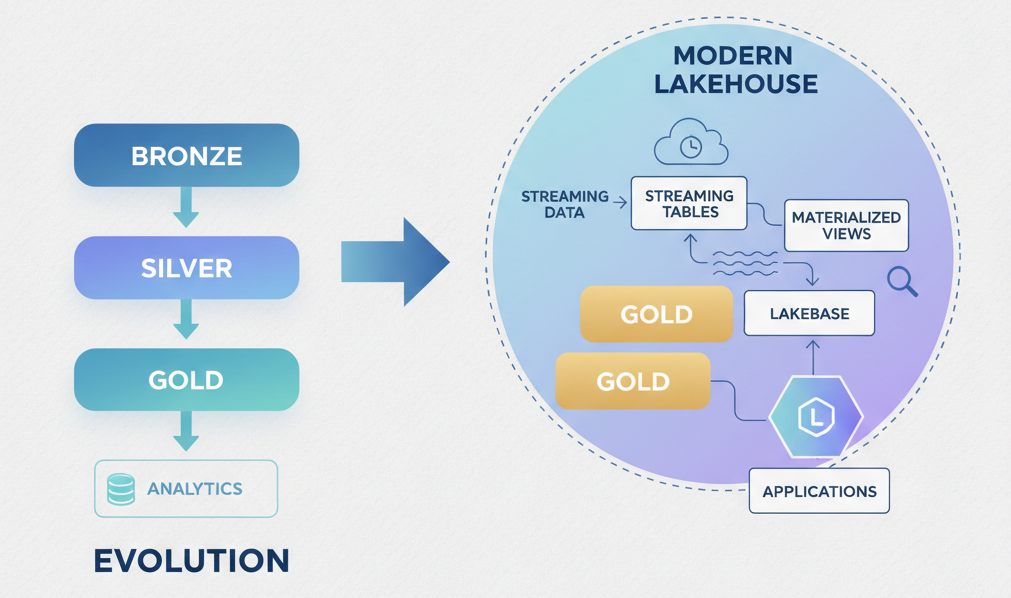
You’ve probably heard about the medallion architecture. Bronze, silver, gold. It’s been the gold standard for data lakehouse design for years. Neat layers. Clear progression. Easy to explain in a slide deck. But if you’re building modern data systems on Databricks, treating medallion as the whole answer just got you halfway there.
The platform has evolved. Your approach should too.
The Medallion Myth
The medallion architecture isn’t wrong. It’s incomplete.
Bronze → silver → gold represents incremental refinement through staging and transformation layers. Raw ingestion, cleansing, then analytics-ready datasets. It’s a perfectly sensible mental model. And Databricks still documents it as the foundational pattern.
Here’s the thing: foundational doesn’t mean sufficient.
Teams who stop at “we’ve got medallion sorted” are leaving architectural capabilities on the table. Specifically, they’re missing streaming tables, materialized views, Lakeflow pipelines, and Lakebase integration. These aren’t nice-to-haves. They’re table-stakes for real-time data systems, aggregation efficiency, and hybrid OLTP/OLAP workloads. The question isn’t whether medallion is obsolete. It’s whether you’ve built only medallion and called it done.
Why Medallion Alone Doesn’t Cut It Anymore
Three reasons teams hit walls with pure medallion thinking:
Real-time ingestion complexity. Bronze tables passively wait for batch loads. That works until your business needs low-latency signals, customer clickstreams, fraud flags, inventory updates. Manually orchestrating streaming ingestion into medallion layers feels wrong because it is. You’re forcing event data through a batch-optimized structure.
Redundant computation. The silver layer does initial transformation. The gold layer aggregates. What happens when analytics teams need the same aggregation in three different dimensional cuts? You replicate the logic, fragment ownership, and create maintenance debt. Materialized views solve this by pre-computing aggregations once and refreshing them automatically.
Schema stiffness. Medallion layers assume data flows downstream cleanly. But the real world is messier: late-arriving facts, retroactive corrections, upstream schema changes. Delta Lake’s schema evolution helps, but without explicit materialized views and streaming table patterns, you’re patching problems instead of designing around them.
The core issue: medallion is about layering data refinement. Modern systems need concurrent patterns for different access needs.
What The Platform Actually Recommends Now
Here’s what Databricks is actually positioning as the modern approach:
Streaming tables for real-time ingestion. Instead of treating streaming as an afterthought, use streaming tables to incrementally process new data as it arrives. They integrate directly with medallion layers, ingest at bronze, transform through silver via streaming logic, land aggregations in gold. Incremental processing means you’re not recomputing history; you’re just handling deltas.
Materialized views for automated aggregations. Define your analytical views once. Materialized views pre-compute them and refresh automatically based on upstream changes. No redundant logic. No manual refresh schedules. Just declare what you need, and the platform ensures it stays current.
Lakeflow Spark Declarative Pipelines. This is the connective tissue. Instead of writing imperative ETL jobs, you declare data dependencies and transformations. The framework handles scheduling, error handling, and testability. It’s a counterweight to chaotic orchestration layers.
Lakebase for OLTP data. Not everything belongs in Delta Lake from the start. Lakebase brings PostgreSQL-compatible transactional data into Databricks. Now you can join transactional tables and Delta tables in the same SQL query. No ETL pipeline to move the OLTP data; no data gravity pulling you toward multiple systems.
Unity Catalog for unified governance. Across workspaces, across regions, across users, govern data and AI assets from one place. Access controls, lineage, auditing. Medallion doesn’t inherently solve governance; Unity Catalog does.
The shift: from “process everything through layers” to “choose the right pattern for each data need.”
Rethinking Your Data Model
If you’re designing a new lakehouse or rearchitecting an existing one, here’s the decision framework:
Start with ingestion patterns, not layers. Ask: Is this data streaming? Batch? Transactional? Stream it in with streaming tables if it’s event-driven. Batch-load if it’s periodic snapshots. Use Lakebase for transactional sources that need ACID guarantees and direct SQL joins. Then layer medallion transformations on top.
Model for access patterns, not just refinement. Medallion layers assume linear flow: raw → clean → ready. Real workloads are messier. Some users need granular detail (silver). Others need aggregations (gold). Materialized views let you serve both without duplicating silver logic. Define views at the finest grain you need; materialize the aggregations that get queried repeatedly.
Treat schema evolution as architectural. Delta Lake handles schema changes gracefully, but design for them explicitly. Use streaming tables at each medallion level; they’re more forgiving of upstream changes than static batch loads. Materialized views isolate downstream consumers from certain schema shifts because the view definition becomes the contract.
Push governance to the platform. Don’t try to enforce data ownership and access controls manually. Unity Catalog makes this native. Enable it early. Govern tables, not folders.
Architecture in Practice
Here’s what this looks like in a moderately complex scenario:
You have e-commerce transaction data (batch daily), user event streams (Kafka), and product master data (ERP system with ACID requirements).
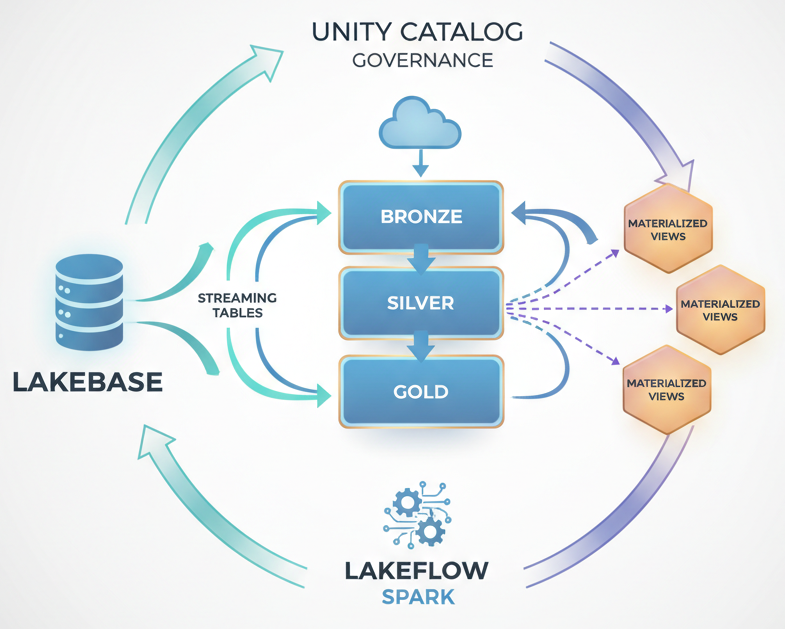
- Ingest layer: Streaming table for events. Batch load for transactions. Lakebase connection for product master. All land in bronze.
- Transformation layer: Streaming tables for cleansing and early aggregations (silver). Joins between transactional and dimensional data happen here. This layer can be real-time if events flow continuously.
- Serving layer: Materialized views on top of silver for BI dashboards (order counts, revenue by product) and materialized views for ML features. These refresh incrementally based on medallion layer changes.
- Orchestration: Lakeflow Spark pipelines declare dependencies between ingestion, transformations, and materialized view refreshes. One system owns scheduling and retry logic.
- Governance: Unity Catalog secures access to bronze/silver/gold tables, views, and Lakebase data. Lineage tracks where every dataset comes from.
Events flow real-time. Transactions flow daily. Both converge in medallion layers. Aggregations refresh automatically. One platform. One catalog.
That’s not medallion. That’s the modern lakehouse.
Business Impact: Speed, Cost, Governance
Faster insights. Streaming tables mean real-time signals flow from ingestion to aggregation. No waiting for daily batch jobs to complete before dashboards update. Real-time materialized views mean BI tools get pre-computed answers instantly.
Lower compute costs. Materialized views compute once and refresh incrementally, not on every query. Streaming tables process only deltas, not historical data. Lakebase avoids unnecessary ETL to move transactional data. You’re paying for actual processing, not rework.
Unified governance. One catalog. One access control layer. No shadow data lakes or untracked datasets. Auditing and lineage happen automatically. Compliance becomes embedded, not bolted on.
Reduced operational burden. Lakeflow pipelines reduce orchestration overhead. Declarative dependencies are easier to test and maintain than hand-coded DAGs. Materialized views eliminate the need to manually manage aggregation refresh schedules.
The Trade-Offs You Should Know
Streaming tables add operational complexity if your ingestion sources are unreliable. If your Kafka topics are spiky or your connectors frequently fail, you’re managing error states instead of just data flow. Plan for that.
Materialized views use storage. Pre-computed aggregations are space-efficient compared to recomputing them, but they’re not free. You’re trading storage for query speed. In a cost-conscious environment, that trade-off isn’t always obvious.
Lakebase introduces another moving piece. It’s transactional data inside Databricks, which is elegant, but it means you’re managing OLTP semantics alongside OLAP patterns. If your team hasn’t done that before, there’s a learning curve.
Unity Catalog governance is powerful but requires discipline. If you rush through catalog setup, you’ll have a permissioning structure that’s hard to unwind.
When Medallion-Plus Matters. When It Doesn’t.
Use this approach if:
- You have both batch and streaming data sources (most modern enterprises do).
- You serve both operational dashboards (which need fresh data) and analytical reports (which can be slightly stale).
- You have transactional systems that drive your lakehouse (and don’t want to ETL the data out separately).
- Governance and data discovery are non-negotiable (regulated industries, multi-team organizations).
- You need to minimize query latency for high-concurrency BI tools.
Pure medallion is probably fine if:
- Your data sources are entirely batch (quarterly reporting only).
- You have a small team with low governance overhead.
- You’re building throwaway analytics (proof of concept, time-boxed research).
- Your business doesn’t penalize delayed insights.
Be honest about which camp you’re in.
Real Scenario: The Subscription SaaS Company
A subscription SaaS platform had built medallion layers: bronze for raw event logs, silver for cleaned customer events and transactions, gold for reporting tables.
Problem: Dashboards refreshed nightly. When the sales team wanted intraday churn signals, the architecture couldn’t deliver without hand-coding new pipelines.
Solution: Introduced streaming tables at silver for event processing. Materialized views on gold for key business metrics (churn probability, ARR, cohort health). Lakeflow orchestrated the dependency chain. Within two weeks, dashboards were real-time. No new infrastructure. No manual ETL.
That’s the win medallion-plus architecture delivers.

The Final Take
Medallion architecture is still the conceptual spine of good data systems. It’s not broken.
But if you’re building on Databricks in 2026 and your architecture ends at bronze, silver, gold, you’re leaving real-time capabilities, governance depth, and operational efficiency on the table.
The modern recommendation isn’t to abandon medallion. It’s to layer streaming tables, materialized views, Lakeflow pipelines, and Lakebase integrations on top of and alongside it.
The lakehouse has matured. Your data architecture should too.