Table of Contents
The pitch sounds irresistible: autonomous agents that coordinate, delegate, and solve problems without human intervention. Multiple AI models working in concert, each handling what it does best. Self-improving systems that learn and adapt. It’s the future of enterprise AI. It’s also where most organizations stumble.
Multi-agent systems represent a fundamental shift from “AI as a tool” to “AI as infrastructure.” But building them isn’t about throwing more models at a problem. It’s about orchestration, observability, and the unglamorous work of making sure your AI doesn’t confidently do the wrong thing while you’re asleep.
Databricks has quietly become the platform where enterprises actually pull this off. Not because it has flashy agent features (though it does), but because it forces you to think about the hard parts first: How do you know if an agent is working? What happens when it fails? How do you evaluate whether “autonomous” actually means “better”?
Let’s talk about what you’re actually signing up for.
The Multi-Agent Illusion (And Why Most Fail)
When enterprises talk about multi-agent systems, they’re often imagining something like a consulting firm where specialized experts collaborate. One agent handles customer research. Another writes proposals. A third manages client relationships. They hand off work, coordinate on complex problems, and somehow produce better outcomes than any single system.
The reality? Most organizations get stuck at the hand-off.
A customer service agent can summarize complaints. A data agent can fetch relevant metrics. A generation agent can draft responses. But making them work together, having each know when to defer to the other, how to interpret signals, when to escalate, that’s where the complexity explodes.
The fundamental problem: You can’t manage what you can’t see. And multi-agent systems are inherently opaque.
Agent A calls Agent B, which queries a database, which returns ambiguous results that Agent C tries to interpret. Something goes wrong. Was it the routing logic? The model’s understanding of context? Bad data? A hallucination three steps up the chain. Without deep visibility into every decision point, every function call, every trace through the system, you’re running on big assumptions.
Databricks doesn’t solve this by adding more agents. It solves it by adding relentless observability.
The Observability Foundation: Tracing Isn’t Optional
Here’s what separates theoretical multi-agent systems from ones that actually work in production:
MLflow Tracing captures the DNA of every agent interaction. Not just “Agent A ran for 2 seconds.” But every model call, every tool invocation, every logical branch. You can see exactly which tokens were passed where, which prompts triggered which decisions, where latency lives, and where quality breaks down.
This matters because multi-agent systems fail in ways single systems don’t. A model might perform brilliantly in isolation but make brittle assumptions when coordinating with other agents. An agent might work fine 95% of the time and catastrophically fail on the edge cases that matter most to your business.
With trace-level observability, you’re not guessing about failure modes. You’re identifying them in real time and understanding their root cause. Was the router agent sending requests to the wrong specialized agent? Did context get lost in translation between systems? Did a vectorized search return off-topic results that cascaded through downstream decisions?
The decision: Before you deploy any multi-agent system, ask: Can I trace every function call, every model invocation, every decision branch? If the answer isn’t a clear yes, you’re building a black box that happens to have multiple components.
Evaluation: How to Know If Your Agents Are Actually Working
This is where most enterprises get it wrong. You can build a multi-agent system that runs. Agents execute, hand off work, produce outputs. But are they actually better than a single agent? Are they reducing hallucinations? Improving accuracy on complex research tasks? Actually, making your business more efficient?
Most organizations never answer these questions. They launch, assume it’s working because it’s more sophisticated, and hope for the best.
Databricks enforces a different discipline through its agent evaluation framework.
LLM-judged quality scoring lets you assess outputs against business-specific criteria. Not just “Is this grammatically correct?” but “Did the agent cite reliable sources?” “Was the evidence sufficient to support the conclusion?” “Did it respect the customer’s original intent?”
You can also implement scorers for retrieval quality (Is the agent pulling the right data?) and response faithfulness (Is the agent representing that data accurately, or did it drift into speculation?).
The elegant part: These evaluations integrate directly with MLflow experiments. Every trace gets scored. Every agent configuration gets compared. You’re not relying on anecdotes or cherry-picked examples. You’re tracking quality metrics across your full evaluation dataset.
Critical decision point: How will you measure whether a multi-agent system is better than alternatives? If you don’t define those metrics before you build, you’ll never truly know if the added complexity is worth it.
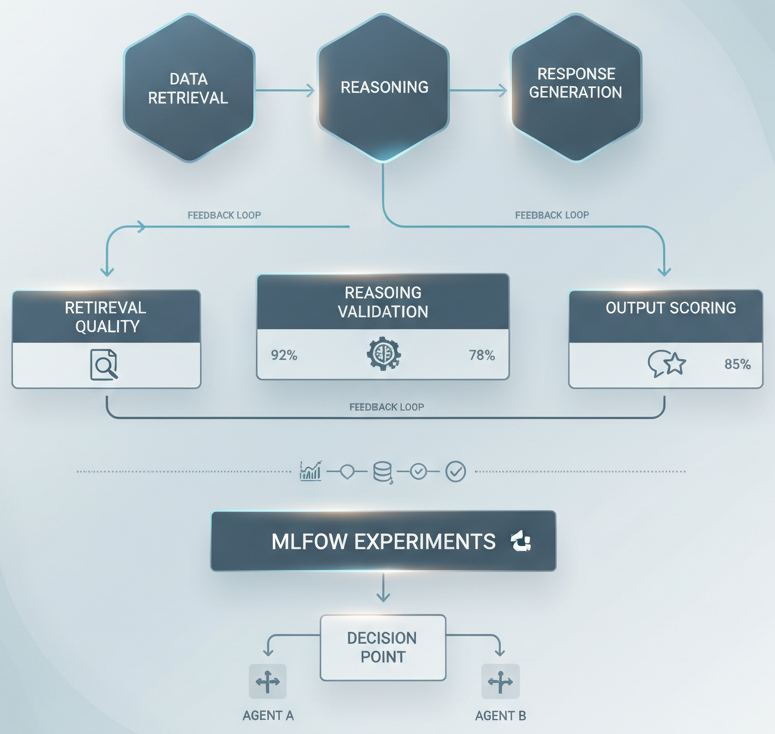
The Routing Problem: Not All Agents Are Equal
One of the sneakiest problems in multi-agent systems is what happens when you have more than one agent but no clear rule for when to use each one.
A data analyst agent is great for metrics. But what if a user’s question actually needs market research? A research agent might be better. Or both, in sequence, with one feeding results to the other? How does the system decide which path to take?
Databricks gives you supervisor agents (available by default in March 2026 workspaces) that handle this orchestration. But more importantly, it lets you build custom routing logic through Databricks Apps. You can implement intelligent dispatching: evaluating the incoming request, determining which specialized agents are relevant, deciding on execution order and context-sharing rules.
The trap: You might assume routing logic is simple. User asks about “customer churn” send to the customer success agent. Reality is messier. The user might want historical trends (data agent), predictive models (ML agent), or tactical retention strategies (ops agent). Or all three in a specific sequence.
What you need to know: Multi-agent systems aren’t “set and forget.” Routing logic is a core product. You’ll iterate on it constantly as you see how real users interact with the system. Plan for that from the start.
Foundation Models: Building the Right Stack
Here’s a decision most enterprises don’t think carefully about: Which models should power which agents?
You could use the same large, capable model for everything. It’s simple. But large models are slow and expensive. Some agents don’t need that much power. A routing agent deciding “send this to customer service or accounting” doesn’t need GPT-4-level reasoning. Databricks lets you mix and match.
Foundation Model APIs give you pre-configured models on a pay-per-token basis. You can use a large model where you need deep reasoning, a lightweight model for quick decisions, and specialized models for specific domains. You deploy directly from Unity Catalog with a single click.
The approach: Build your multi-agent architecture with different models in mind. Use smaller models for high-volume, low-complexity decisions (routing, classification, filtering). Reserve larger models for complex reasoning where quality really matters. This compounds your efficiency and reduces costs dramatically.
Framework question: Can your multi-agent system accommodate different models at different decision points, or are you locked into a one-size-fits-all approach? If the latter, you’re leaving both performance and budget on the table.
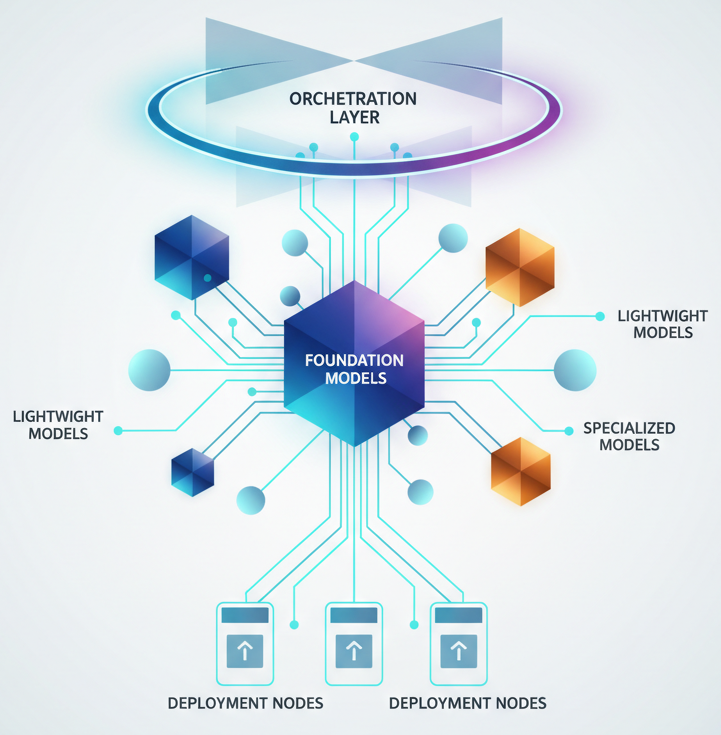
The Intelligence That Matters: AI Functions for Data Pipelines
Here’s where multi-agent thinking gets genuinely interesting for enterprises: AI functions let your data analysts invoke AI directly in SQL.
Imagine a data analyst running a query that not only returns metrics but interprets them in context, flags anomalies, or generates narratives about what the data means. No handoff to a data science team. No separate AI system. The AI is embedded in the data pipeline itself.
This is multi-agent thinking at the infrastructure level. The database agent can call analytical agents. Query optimization agents can work in parallel with interpretation agents. SQL-native AI means less moving data between systems, less latency, and more agency for analysts.
Why this matters: Every data movement between systems is a failure point. Every handoff is an opportunity for context to get lost. Building multi-agent systems that live in your data platform eliminates entire classes of coordination problems.
The Feedback Loop: Quality Signals From the Real World
Your evaluation dataset tells you if agents work in controlled conditions. But production is never controlled.
Real users interact with your system differently than test cases. They ask weird questions. They combine requests in unexpected ways. They have implicit context you didn’t model. Some interactions reveal that your agents are misaligned or making subtle errors.
Databricks lets you implement quality feedback mechanisms directly into the user experience. “Was the supporting evidence sufficient?” “Did this answer your actual question?” Simple feedback, collected at scale, flows back into your evaluation dataset.
Your evaluation pipeline evolves. You discover failure modes you didn’t anticipate. Your multi-agent system gets better.
The mindset shift: Launch multi-agent systems expecting they’ll be wrong in specific ways. Build feedback infrastructure from day one. Treat production as a continuous evaluation environment, not a “done” state.
Decision Framework: Should You Build Multi-Agent?
Multi-agent systems are genuinely powerful. But they’re also genuinely complex. Here’s the honest framework:
Build multi-agent if:
- Your problem genuinely has multiple specialized skill domains that benefit from different models or tools
- Quality monitoring and iterative improvement are core to your strategy
- You can invest in observability infrastructure from the start
- Your use case has enough volume to justify the operational overhead
Don’t build multi-agent if:
- A single well-designed agent solves 80% of your problem
- You can’t clearly define what “better” looks like
- You don’t have the infrastructure (tracing, evaluation, feedback) to monitor it
The organizations winning with multi-agent AI aren’t the ones building the most agents. They’re the ones building systems they can see, measure, and improve continuously.
Databricks makes that possible. But it requires a different mindset than traditional AI deployment. You’re not just launching a model. You’re building a system that keeps itself honest.
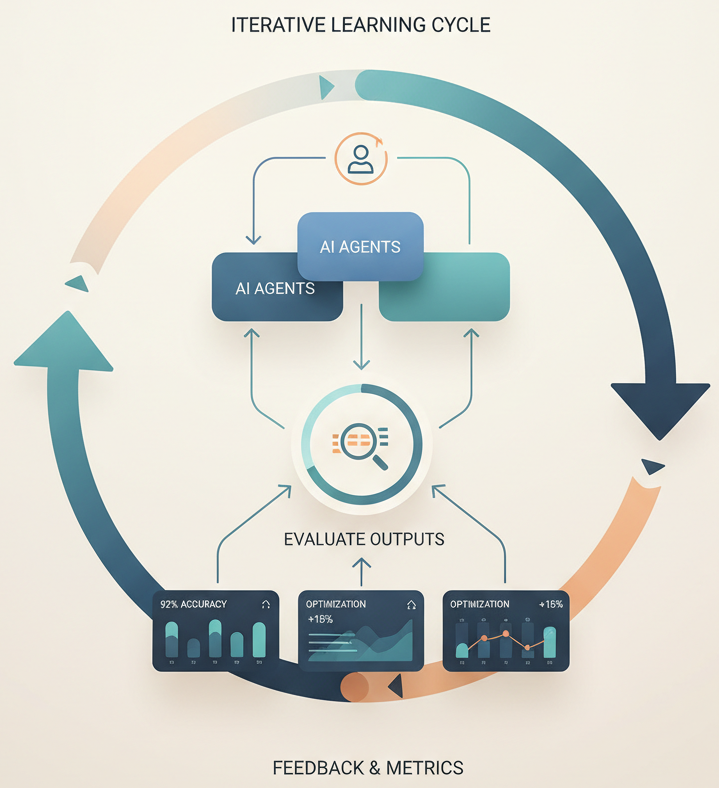
The Real Edge: Orchestration as Competitive Advantage
The future of enterprise AI isn’t “bigger models.” It’s smarter systems that route work, evaluate quality, and improve continuously.
Multi-agent systems on Databricks work because they force the right conversation: Not “Can we build this?” but “How will we know it’s working? How will we improve it? What happens when it fails?”
That’s the architecture that actually wins in production.